gepar.do blog
Все, что вы не хотели знать про Юникод, но придется
Немного предупреждений
В посте используется очень много разных символов Юникода. Лучше читайте на самых современных версиях браузера и операционной системы, если это возможно. Иначе некоторые символы могут просто не отобразиться. Впрочем, это не гарантия, и что-то может неверно отображаться даже на самых последних версиях.
Стандарты Юникода и его терминология написаны на английском. Возможно, у некоторых терминов есть каноничный русский перевод, но я его не знаю, поэтому перевожу термины как хочу (а чаще просто транслитерирую без перевода). Чтобы мои переводы не вызывали излишней путаницы, для каждого термина в скобочках обычно указан его оригинал на английском.
Вступление и философские вопросы
Все мы сталкивались с Юникодом. Вернее, постоянно сталкиваемся с ним. Даже прямо сейчас, когда вы читаете эти буквы.
Что такое Юникод? Многие на этот вопрос наверняка ответят что-то вроде «таблица символов». Но здесь возникает другой, более философский вопрос: а что такое символ? В русском тексте все просто: одна буква, цифра, знак препинания или пробел — один символ. В английском тоже. А в общем случае все становится сложнее:
- буква À — это один символ A, или же два: буква A и значок ударения над ней?
- а если таких надстрочных значков становится много и получается Ẵ?
- а если гласные пишутся под или над согласными, как, например, в тибетском (ལྷ་སའི་སྐད་) и иногда в деванагари (देवनागरी)?
- а если мы используем корейский хангыль (한글), где буквы сгруппированы по слогам (한글)?
- а стоит ли точно так же разбирать китайские иероглифы на элементы?
- а многоточие — это три символа точки или один большой символ?
- а знаки пунктуации вроде ?! и !?
- считать ли хорватскую букву dž одним символом? А другие диграфы в разных языках?
- считать ли одним символом лигатуры вроде fi?
И даже если не учитывать все эти сложные случаи, можно вспомнить, что человечество все еще до сих пор не договорилось, является ли перевод строки одним символом или двумя.
Трудности возникают и тогда, когда надо понять, что считать одним символом, а что разными:
- должны ли быть латинская e и русская е одним символом?
- а русская е и сербская е?
- а русская б и сербская б, которые имеют слегка разное написание? (если здесь не видно разницы, то вот картинка)
- а ς, вариант греческой буквы σ, который пишется только на конце слова?
- а что насчет арабских букв, которые в начале, в середине и в конце слова имеют разное написание?
- а что насчет математического оператора суммы ∑ и греческой буквы Σ?
- а обозначение сопротивления Ω и греческая Ω?
- должны ли курсивный и обычный варианты быть разными символами?
{kind=link}
Надеюсь, из примеров выше хорошо видно, что определить понятие «символ» не так просто.
Создателям Юникода пришлось подумать и решить, что является символом, а что нет. Сделали они это путем многочисленных костылей компромиссов, многие из которых мы далее и увидим.
Зачем нужен Юникод
Сначала мир был простым, компьютеры были большими, а людям в США, которые использовали эти компьютеры, хватало обычной латиницы. Поэтому они придумали ASCII — семибитную кодировку, которая включала в себя 128 символов.
Время шло, компьютеры распространялись по миру, и пользователи хотели, чтобы бездушная машина могла понимать их родной язык. Для этого придумали много разных кодировок, каждая из которых предназначалась для своего языка (или нескольких языков сразу). Иногда для одного и того же языка придумывали несколько кодировок. Например, для русского использовались IBM866 (DOS), Windows-1251 (Windows) и KOI8-R (Unix). Еще, кажется, существует ISO-8859-5, но она широкого распространения не получила.
Вместе с кодировками появилась и проблема: чтобы правильно прочитать текст, надо знать, какую кодировку он использует! Многие хорошо помнят боль, когда ñëåòåëà êîäèðîâêà, ой, то есть слетела кодировка, и текст становился совершенно нечитаемым.
Чтобы решить эту проблему, люди создали Одну Кодировку Чтобы Править Всеми. Этой кодировкой и стал Юникод.
На данный момент весь зоопарк кодировок почти полностью ушел в прошлое, и все нормальные люди давно перешли на Юникод.
Выше для простоты мы назвали Юникод кодировкой. Но на самом деле он кодировкой не является, а большинство текстов в мире используют кодировку UTF-8. Но об этом поговорим чуть позже.
Как использовать Юникод
Вы его уже используете каждый раз, когда открываете свой любимый текстовый редактор и набираете в нем текст!
Иногда у вас возникает желание обрабатывать Юникодные строки в своей программе. Хорошая новость: большинство языков программирования работают с Юникодом из коробки. Достаточно использовать лишь стандартную библиотеку вашего любимого языка.
Например, хорошей поддержкой Юникода могут похвастаться Rust, Go и Python. Nim тоже неплох, но для него есть unicodeplus, который содержит чуть больше функций и местами работает более корректно, чем стандартная библиотека.
В C++, увы, все печально. Язык создавался задолго до этого вашего Юникода, и нормально его не поддерживает. Да, в C++ есть «широкие» строки из wchar_t, а еще std::codecvt, который позволяет переводить строки из одной кодировки в другую, но эти вещи, во-первых, создавались во времена, когда миром правила куча разных кодировок, а, во-вторых, достаточно сложны и неприятны в использовании (и я не видел кода, который использует std::codecvt на практике). Как быть?
Одно из решений — использовать популярные крупные C++ библиотеки (например, Boost или Qt), которые реализуют работу с Юникодом. Еще, как вариант, можно воспользоваться библиотекой ICU. Она работает нативно с Си, C++ и Java, а для многих других языков есть биндинги к сишной libicu. Например, вот биндинги для Rust. Пожалуй, из всех существующих библиотек ICU реализует наиболее полную поддержку всех стандартов Юникода, и, скорее всего, реализует все его фичи, которые далее описываются.
Еще, если в вашем любимом языке чего-то не хватает, можно почитать стандарты Юникода и самому реализовать недостающую функциональность. Это не самый быстрый и не самый приятный способ, но иногда имеет право на существование. Стандарты Юникода мы обсудим чуть позже.
Далее мы будем постепенно знакомиться с разными понятиями Юникода и смотреть, как их поддержка реализована в разных языках.
Кодпоинты
Юникод определяет набор символов, каждый из которых имеет свой номер — неотрицательное целое число, начиная с нуля. Как мы увидим далее, понятие «символ» в Юникоде не совсем совпадает с тем, что мы интуитивно считаем символами, поэтому в дальнейшем будем называть эти пронумерованные сущности кодпоинтами (code points).
Сколько кодпоинтов всего существует? Номер кодпоинта не может быть больше, чем 1’114’111 (и далее мы узнаем, почему). На самом деле кодпоинтов меньше: сейчас их используется примерно 150’000.
Кодпоинты часто обозначают в шестнадцатеричном виде, используя префикс U+. Например, русскую букву Ю обозначают как U+042E, а эмодзи кита 🐳 — как U+1F433.
Все пространство из 1’114’112 кодпоинтов разделено на 17 плоскостей (planes) по 65’536 кодпоинтов в каждой. Самая важная из них, нулевая, называется Basic Multilingual Plane (BMP).
Из этих 1’114’112 кодпоинтов доступны далеко не все. Номера с U+D800 по U+DFFF включительно зарезервированы под суррогаты и не соответствуют никакому кодпоинту. Использование суррогатов в тексте не разрешается. Еще 137’468 кодпоинтов зарезервированы под так называемую зону частного использования (Private Use Area). Про суррогаты мы поговорим потом, а вот зону частного использования стоит обсудить сейчас.
Зона частного использования
Состоит из трех диапазонов. Один в BMP (U+E000…U+F8FF), еще два занимают 15 и 16 плоскость почти полностью (U+F0000…U+FFFFD и U+100000…U+10FFFD).
Эта зона отведена для символов, которых нет в Юникоде. Например, пусть вы большой поклонник творчества Толкиена и хотите писать тексты на эльфийском языке квенья. Букв языка квенья в Юникоде, увы, нет, поэтому вам придется создать свой шрифт, который отображает некоторые символы из этой частной зоны как эльфийские буквы.
Еще зона частного использования полезна для иконочных шрифтов, таких как FontAwesome. Можно нарисовать кучу иконок для своего сайта, присвоить им кодпоинты из частного диапазона и упаковать в шрифт!
Конечно же, чтобы люди смогли читать ваши эльфийские тексты и правильно видеть иконки, им понадобится правильный шрифт. Иначе магия не работает, потому что, увы, мы находимся в реальном мире, а не в Средиземье.
Документация
Как у любого уважающего себя стандарта, у Юникода есть толстенные документы, которые все и описывают. Найти их можно на сайте unicode.org.
Кроме человекочитаемого текста, Юникод включает в себя машиночитаемый Unicode Character Database, который состоит из нескольких десятков текстовых файлов. Найти все эти файлы можно здесь, а их описание можно найти здесь. Каждая уважающая себя библиотека, которая поддерживает Юникод, использует эти текстовые файлы. Например, в стандартной библиотеке Rust их используют аж дважды: раз и два. Конечно же, никто не вставляет файлы вроде UnicodeData.txt в бинарник в исходном виде и тем более не скачивает их в рантайме; их обычно используют при сборке библиотек, генерируя из них производительный код и данные для него.
Рассмотрим часть из этих файлов, а на некоторые другие мы будем постепенно ссылаться позже.
UnicodeData.txt
Файл UnicodeData.txt описывает все кодпоинты.
Например, описание кодпоинта U+042E представлено вот такой строчкой:
042E;CYRILLIC CAPITAL LETTER YU;Lu;0;L;;;;;N;CYRILLIC CAPITAL LETTER IU;;;044E;
Видно, что строчка состоит из нескольких полей, отделенных символом ;. Некоторые поля опущены, потому что не применимы к данному кодпоинту.
Что можно сказать об этом кодпоинте по его описанию?
- Его номер в шестнадцатеричной записи:
042E. - Его имя:
CYRILLIC CAPITAL LETTER YU. - Его категорию:
Lu. В нашем случае это Letter Uppercase (т.е. заглавная буква). Все возможные категории описаны здесь. Первая буква категории может бытьL(Letter),M(Mark),N(Number),P(Punctuation),S(Symbol),Z(Separator) илиC(Other), вторая буква категории дальше уточняет тип кодпоинта (например, для буквы задает, в каком она регистре). - Его числовое значение. У буквы Ю оно, конечно же, отсутствует. Зато оно есть, например, у цифр. А еще — у чисел в кружочках вроде ㊷. А еще — у восточных арабских цифр, которые, в отличие от наших арабских цифр, используются в арабских странах (не запутайтесь!) А все для того, чтобы арабы могли ввести в Python
int('١٣١٠٧٢')и получить заветное131072. - Результат преобразования кодпоинта в другие регистры. Например, Ю можно преобразовать в нижний регистр и получить U+044E, то есть ю. К преобразованию в другой регистр мы еще вернемся.
- Использует ли кодпоинт порядок слева направо или справа налево (нужно, например, для арабского языка). Буква Ю — часть кириллицы, а, значит, пишется слева направо (что записывается как
L). Про это тоже поговорим позже. - Еще много всего интересного.
Таким образом, UnicodeData.txt может дать много полезной информации о кодпоинтах.
При парсинге этого файла следует учитывать один нюанс. Иногда информация об отдельных кодпоинтах в нем отсутствует, а вместо этого задается сразу целый диапазон. Например, для китайских иероглифов:
3400;<CJK Ideograph Extension A, First>;Lo;0;L;;;;;N;;;;;
4DBF;<CJK Ideograph Extension A, Last>;Lo;0;L;;;;;N;;;;;
Если этот нюанс не учесть, можно допустить багу и перестать считать китайские буквы буквами. Ровно такая бага была в Nim, пока я не пришел и не исправил.
Blocks.txt
Содержит информацию о блоках Юникода. Каждый кодпоинт принадлежит какому-то блоку. Блоки обычно содержат кодпоинты одной и той же письменности или похожие по назначению. Например, почти весь текст, который вы сейчас читаете, использует блоки «Basic Latin» и «Cyrillic». Блок не обязательно содержит всю письменность целиком, так, существуют «Cyrillic Extended-C» и «Latin Extended Additional», которые содержат всевозможные дополнения для латиницы и кириллицы соответственно (и таких дополнений много!). Существуют еще, например, блоки «Miscellaneous Mathematical Symbols-A» для математических символов, и «Miscellaneous Symbols and Pictographs», который содержит многие эмодзи.
Scripts.txt
Указывает, к какой письменности принадлежит кодпоинт (кириллица, латиница, грузинский, общий для разных письменностей и т.д.).
DerivedCoreProperties.txt
Рассмотрим еще DerivedCoreProperties.txt. Слово «derived» в названии файла означает, что он не задает какой-то новой информации, а собран из других файлов Unicode Character Database по определенным правилам. В нашем случае используются данные из PropList.txt и информация о категории из UnicodeData.txt.
Если открыть этот файл, то там будет написано что-то вроде
# Derived Property: Uppercase
# Generated from: Lu + Other_Uppercase
0041..005A ; Uppercase # L& [26] LATIN CAPITAL LETTER A..LATIN CAPITAL LETTER Z
...дальше еще куча диапазонов
Здесь написаны как и сами диапазоны, которые удовлетворяют свойству Uppercase, так и правило, по которому эти диапазоны и были сгенерированы.
Все эти знания про файлы Unicode Character Database плавно подводят нас к следующему интересному вопросу.
Что такое буква?
Во многих языках программирования существуют функции вида isalpha(), isdigit() и похожие. Когда-то такие функции были придуманы в Си для ASCII, и их реализация была относительно простой и понятной.
В случае с Юникодом ответ на вопрос «является ли кодпоинт буквой», сложнее, и разные языки программирования имеют свое мнение на этот счет.
Например, в Go существует функция unicode.IsLetter(), которая буквально проверяет, что категория кодпоинта в UnicodeData.txt начинается с L.
Rust идет по другому пути; его is_alphabetic проверяет свойство Alphabetic из DerivedCoreProperties.txt, которое является надмножеством категории L. Например, кодпоинт U+0345 COMBINING GREEK YPOGEGRAMMENI имеет категорию Mn, но при этом является Alphabetic.
Nim в isAlpha, как и Go, считает только кодпоинты категории L.
Python в isalpha соглашается с Nim и Go.
Про стандартный isalpha в Си и C++ я говорить особо не хочу; эти языки создавались задолго до появления Юникода, и что они вернут для не-ASCII кодпоинтов, зависит от реализации, системной кодировки и фазы Луны.
Прав ли Rust, что определяет буквы не так, как Go, Nim и Python? Или правы все остальные? Вопрос философский. Я считаю, что все правы по-своему.
Конечно же, возвращаемое значение всех описанных выше функций еще зависит от того, какая версия Юникода поддерживается языком, но об этом чуть позже.
Версии и обновления
Юникод не зафиксирован раз и навсегда в камне. Верно скорее обратное: каждый раз, когда археологи где-то находят высеченные в камне символы, их рано или поздно добавляют в Юникод. Стандарт постоянно дорабатывается, и добавляются новые кодпоинты. Первая версия Юникода вышла аж в 1991 году. На момент написания поста последняя версия — 16.0, и каждый год выходят обновления!
Чтобы обновления Юникода не ломали существующие тексты и программы, существуют гарантии обратной совместимости. Подробнее про них можно почитать здесь.
Например, гарантируется, что ранее добавленный кодпоинт никогда не будет удален. Также у добавленного кодпоинта никогда не поменяется его имя. А вот категория поменяться может, но при этом «character properties will not be changed in a way that would affect character identity». Также в новой версии у кодпоинта может появиться его вариант в верхнем или нижнем регистре.
Существует еще множество других гарантий. Некоторые из них мы обсудим позже, если понадобится.
Определение категории кодпоинта
Выше мы видели, что Rust отличает буквы от не-букв не так, как многие другие языки. А Go вообще позволяет проверить кодпоинт на принадлежность любой категории. Можно ли в Rust добиться такого же поведения, как в Go?
Можно, но придется использовать сторонние крейты. Один из самых популярных — unicode_categories, но увы, он не обновлялся уже 8 лет и не работает с новыми версиями Юникода. Не используйте его. Лучше используйте, например, finl_unicode. Он поддерживает новые версии Юникода, а еще хвастается в README, какой он blazingly fast.
Чтобы определить категорию кодпоинта в Nim, можно, например, использовать пакет unicodedb.
В Python можно использовать встроенный модуль unicodedata.
Как isalpha и определение категории кодпоинта реализованы в коде?
Самая простая возможная реализация выглядела бы так: распарсить Unicode Character Database, построить список всех алфавитных кодпоинтов и выполнить бинарный поиск, чтобы понять, есть ли заданный кодпоинт в нашей таблице.
Этот алгоритм можно оптимизировать. Например, заметим, что алфавитные кодпоинты часто не расположены в одиночку, а сгруппированы в диапазоны. То есть, можно записать список всех диапазонов, и проводить бинарный поиск уже по диапазонам.
Также полезно оптимизировать частый случай, когда кодпоинт лежит в ASCII.
А как оно работает в реальных языках программирования? Если коротко, то костылями, ad-hoc решениями и большими таблицами с данными.
Посмотрим, к примеру, на Rust. Вся реализация написана тут. В этом файле очень много всяких таблиц. Конечно же, они написаны не руками, а сгенерены с помощью вот этого кода. Не будем разбирать, как все это работает (код довольно сложный), но в целом здесь основная идея проста: разбить все пространство кодпоинтов на диапазоны и использовать бинпоиск. Еще видно, что авторы стремились сделать так, чтобы таблицы для поиска получились компактными.
А вот в Go все реализовано проще. Все нужные таблицы хранятся в типе RangeTable. За исключением некоторых оптимизаций, каждая таблица — это просто отсортированный набор диапазонов. В каждом диапазоне есть еще Stride, который указывает, что подходят не все кодпоинты в диапазоне, а только каждый Stride-й. Я не знаю, зачем нужен Stride, но подозреваю, что это просто небольшая оптимизация. Конечно же, чтобы проверить принадлежность кодпоинта заданной категории, надо просто выполнить бинпоиск по одной из таблиц.
Остальные языки я оставлю, пожалуй, в качестве упражнения читателям.
Графемные кластеры
С кодпоинтами не все так просто! Некоторые из них не образуют самостоятельный, значимый символ на экране, а делают это лишь в комбинации с другими кодпоинтами.
Например, кодпоинт « ̌ » полезен только в сочетании с какой-то буквой. Например, если перед ним поставить букву Ы, то получается Ы̌.
Или хангыль, который упоминался выше. В Юникоде существуют как отдельные кодпоинты для каждой «группы» букв (т.е. 한글 будет состоять из двух кодпоинтов), так и отдельные кодпоинты для каждой буквы, которые называются «чамо» (т.е. 한글 будет состоять из шести кодпоинтов).
Или эмодзи. В мире победившего diversity придумали кодпоинты цвета кожи (🏿, например), которые могут менять цвет кожи многим эмодзи. Например, можно из 👍 сделать 👍🏿.
Еще в мире эмодзи можно составлять из людей семьи разной степени традиционности. Например, эмодзи 👨👩👧👦 состоит из семи кодпоинтов: четырех эмодзи людей и трех кодпоинтов ZERO WIDTH JOINER, которые и соединяют этих людей в семью.
Надеюсь, теперь понятно, почему я перестал выше использовать слово «символ» и заменил его на «кодпоинт». Но тогда нам нужно понятие, которое обозначает символ, каким мы видим его на экране. В Юникоде это называется расширенный графемный кластер (extended grapheme cluster). Он называется «extended», потому что, по некоторым историческим причинам, в Юникоде есть еще и legacy grapheme cluster. Тем не менее, далее для простоты будем звать его просто графемный кластер.
Таким образом, кодпоинты группируются в графемные кластеры. Здесь, кажется, странностей никаких нет, и графемный кластер состоит лишь из подряд идущих кодпоинтов. В простом случае графемный кластер состоит из одного кодпоинта. В непростом случае — из скольки угодно. Семьи из семи кодпоинтов мы уже видели, но это не предел — z̵̲̙̜͚̮̩̠̰̈́å̵̯͊̍̅̈́͌l̶̲̰̾g̴̡̖͍̙͉̣̃͑̈́̐̄͘ͅo̴̖͙̥̽̌̍ позволяет нам иметь графемные кластеры сколь угодно большого размера.
Как разбить текст на графемные кластеры? Для этого существует алгоритм, который в оригинале описан вот здесь. Конечно же, чтобы его реализовать, надо еще использовать описанный выше Unicode Character Database. Не советую самим разбираться во всех тонкостях сегментации, лучше найдите хорошую библиотеку, которая умеет разбивать на графемные кластеры за вас, и наслаждайтесь жизнью. Я здесь разбирать алгоритм тоже не буду: во-первых, мне лень, во-вторых, этот раздел уже и так немаленький, а в-третьих, читать скучный список из всех возможных случаев вы, наверное, не захотите.
Кодировки
Почему «кодировки»? Разве Юникод и так не является кодировкой?
Нет, не является, потому что он лишь присваивает кодпоинтам номера. Чтобы получить кодировку, надо как-то еще представить последовательность кодпоинтов в файле.
К счастью, стандарты Юникода предлагают способы записать кодпоинты в файл, и даже не один! Эти способы и являются кодировками. Они также называются Unicode transformation format, или UTF.
Рассмотрим их подробнее.
UTF-32
Самый очевидный способ. Заметим, что каждый кодпоинт помещается в 32-х битное целое число. Можно просто закодировать эти числа в двоичном виде и записать одно за другим. Этот способ называется UTF-32. Существуют его варианты UTF-32BE и UTF-32LE в зависимости от того, закодируете вы 32-х битные числа в little или в big endian.
Плюсы такого похода очевидны: формат прост как пробка, все кодпоинты занимают одинаковое число байтов, реализуется в три строчки. Но на практике UTF-32 для хранения используют редко, потому что он занимает много места (бо́льшая часть байтов в файле просто будут нулями). Зато UTF-32 используют при хранении строк в памяти, например, так хранит строки Python. Это позволяет легко индексироваться по отдельным кодпоинтам.
UTF-8
На практике чаще всего используют UTF-8. Он несколько сложнее, и кодпоинты в нем занимают переменное количество байтов.
А устроен он так. Первые 2⁷ = 128 кодпоинтов занимают ровно один байт, который равен номеру этого кодпоинта.
Следующие 2¹¹ - 2⁷ кодпоинтов используют два байта, первый из которых имеет формат 110xxxxx, а второй — 10xxxxxx. Вместо x подставляются значащие 11 бит номера этого кодпоинта.
Следующие 2¹⁶ - 2¹¹ кодпоинтов, которые не учтены выше, используют три байта. Первый имеет формат 1110xxxx, следующие два — 10xxxxxx.
Остальные кодпоинты используют четыре байта. Первый имеет формат 11110xxx, следующие три — 10xxxxxx.
Для примера попробуем закодировать кодпоинт номер 1070, в народе известный как русская буква Ю:
- Сначала определяем, сколько байтов нам надо:
- 1070 ≥ 2⁷, одного байта не хватит.
- 1070 < 2¹¹, хватит двух байтов.
- 1070 в двоичной системе — это
10000101110. Записываем эти биты в шаблон110xxxxx 10xxxxxx, получаем11010000 10101110илиD0 AE. - таким образом, кодпоинт 1070 представлен двумя байтами —
D0 AE.
Видно, что UTF-8 строится довольно непросто. Но какие преимущества мы от этого получаем? И какие у него есть недостатки?
Преимущества и недостатки
Преимущества:
- Все старые текстовые файлы в кодировке ASCII читаются абсолютно без изменений.
- Кодировка намного компактнее, чем UTF-32, а языкам, которые используют слегка расширенную латиницу, для большинства кодпоинтов хватает одного байта.
- Небольшие повреждения файла не мешают прочитать весь остальной текст.
- Можно хранить Юникодную строку в
const char *и часто работать с ней как с последовательностью байтов даже не зная, что там лежит UTF-8.- В частности, если требуется найти подстроку в строке, то можно напрямую искать последовательность закодированных в UTF-8 байтов и не пытаться декодировать текст вообще.
- Легко итерироваться по кодпоинтам в обе стороны.
- Для каждого байта легко узнать, какому кодпоинту он принадлежит.
- Если у нас валидная UTF-8 строка, то очень просто за O(1) проверить, является ли ее подстрока с l-го байта по r-й валидным UTF-8. (Этим пользуется Rust, который умеет паниковать, если вы пытаетесь взять ссылку на подстроку не по границам кодпоинтов.)
Недостатки:
- Кодпоинты имеют переменную длину, поэтому некоторые строковые операции занимают O(n) времени и делаются лишь линейным проходом по строке, например:
- найти i-й кодпоинт в строке;
- взять подстроку с i-го по j-й кодпоинт;
- посчитать длину строки в кодпоинтах.
Обычно преимущества сильно перевешивают недостатки. Поэтому UTF-8 используется повсеместно, как при хранении текста, так и при обработке строк во многих языках. Например, Go и Rust хранят строки как UTF-8 (при этом Rust еще требует, чтобы строка всегда была корректным UTF-8, иначе паника). А еще эта кодировка часто дружит со старыми программы на Си, которые не хотят знать ни про какой Юникод, используют только ASCII и хранят все строки в старом добром const char *.
В общем, если вы думаете, в какой кодировке сохранять свои файлы, используйте UTF-8, она великолепна. А еще почти все нормальные люди используют UTF-8.
Теперь поясним подробнее некоторые из преимуществ.
Для начала про ASCII-файлы. Из построения UTF-8 видно, что каждый символ ASCII занимает в UTF-8 ровно один байт, соответствующий его номеру. Поэтому любой ASCII-файл является валидным UTF-8 и читается точно так же, как и в ASCII.
Далее про повреждения. UTF-8 спроектирован так, что удаление, замена или вставка некоторых байтов в текст не приводит к тому, что все остальное становится нечитаемым. Действительно, каждый разумный декодировщик UTF-8, глядя на байт, может понять, какой части кодпоинта он принадлежит:
- байты вида
0xxxxxxxкодируют целый кодпоинт; - байты вида
10xxxxxxвстречаются только в середине или в конце кодпоинта; - байты вида
110xxxxxвстречаются в начале кодпоинта и говорят, что кодпоинт занимает всего два байта; - байты вида
1110xxxxвстречаются в начале кодпоинта и говорят, что кодпоинт занимает всего три байта; - байты вида
11110xxxвстречаются в начале кодпоинта и говорят, что кодпоинт занимает всего четыре байта; - байты вида
11111xxxнекорректные.
Если декодировщик встречает некорректный с точки зрения UTF-8 байт, то он обычно вставляет кодпоинт номер U+FFFD, он же REPLACEMENT CHARACTER, он же �. Для краткости будем его неформально называть «вопросиком». Кроме «вопросика» существует еще «тофу», который используется, если операционная система не знает, как отобразить символ на экране. «Тофу» обычно выглядит как квадратик (а в этом браузере он отображается как ), за что и получил такое название.
Таким образом, если один байт в тексте оказывается поврежден или удален, или если в текст добавился лишний байт, то это сильно не скажется на его читаемости: на месте ошибки окажется «вопросик», а все остальное будет прочитано корректно.
Отсюда же следует и удобство итерирования по кодпоинтам: первый байт нам всегда говорит его длину. А чтобы найти, какому кодпоинту принадлежит байт, достаточно пройтись назад, пропустив все байты вида 10xxxxxx.
UTF-16
Что может быть между 8 и 32? Правильно, 16!
Изначально, когда Юникод только появился, люди наивно предполагали, что 640 КБ 2¹⁶ кодпоинтов хватит всем, и кодировали Юникодные тексты двумя байтами на кодпоинт. Очень быстро эти наивные убеждения разбились об суровую реальность.
Тем не менее, в Эпоху Двухбайтового Юникода появилась очень важные технологии: Win32, Java и JavaScript. Их разработчики приняли решение использовать по два байта на кодпоинт в своих строках. Чтобы позволить этим технологиям дальше существовать и предполагать, что в мире существует всего 2¹⁶ кодпоинтов, как раз и придумали UTF-16.
Идея UTF-16 во многом похожа на UTF-8. Если кодпоинт находится в числе первых 65’536 (то есть, в BMP), то он кодируется просто двумя байтами. Иначе он кодируется… а чем он кодируется, если все 65’536 возможных значений уже заняты? На самом деле, специально для кодировки UTF-16 в Юникоде зарезервировали кодпоинты с U+D800 по U+DFFF включительно, и назвали их суррогатами (surrogates). Эти кодпоинты навсегда зарезервированы и вычеркнуты из Юникода. Кодпоинты с U+D800 по U+DBFF называются верхними (high) суррогатами, а кодпоинты с U+DC00 по U+DFFF — нижними (low) суррогатами.
Так вот, все кодпоинты за пределами базовой плоскости кодируется парой из двух суррогатов (сначала верхнего, потом нижнего). Если кодпоинт имеет номер i, то используется верхний суррогат номер (i - 65536) / 1024 и нижний суррогат номер i % 1024.
Также заметим, что UTF-16, как и UTF-32 бывает big endian и little endian.
Рассмотрим, например, кодпоинт U+1F433, более широко известный как кит 🐳, он же SPOUTING WHALE.
Он не находится в BMP, потому что его код больше, чем 65’535. Значит, его нужно кодировать двумя суррогатами: верхним с кодом 0xd800 + (0x1f433 - 65536) / 1024 = 0xd83d и нижним с кодом 0xdc00 + 0x1f433 % 1024 = 0xdc33. Тогда в UTF-16LE мы получаем последовательность байтов 3D D8 33 DC.
Таким образом, каждый кодпоинт в UTF-16 кодируется либо двумя байтами, либо четырьмя.
Нетрудно видеть, что максимальный номер кодпоинта, который может быть представлен в UTF-16, равен 2²⁰ + 2¹⁶ - 1 = 1’114’111. Именно поэтому кодпоинты с бо́льшими номерами в Юникоде просто запрещены. Впрочем, этого миллиона хватит еще надолго, а потом, я надеюсь, что-то придумают.
В плане удобства работы у UTF-16 имеются все те же преимущества, что у UTF-8 (только вместо последовательности байтов придется иметь дело с последовательностью uint16). И есть те же недостатки: это кодировка переменной длины, и получение кодпоинта по его индексу работает долго.
UTF-16 занимает больше места, чем UTF-8, если текст использует латиницу. Для кириллицы это тоже верно. Для китайского верно обратное (большинство иероглифов занимают три байта в UTF-8 и два байта в UTF-16). Здесь внизу статьи можно найти сравнение, для каких языков UTF-8 компактнее, а для каких наоборот (а еще можно в целом увидеть, насколько компактно кодируется текст на том или ином языке в целом).
Тем не менее, большинство нормальных людей сейчас не используют UTF-16 для хранения и пересылки текста, а используют UTF-8. Используйте и вы тоже.
BOM
Выше мы видели, что существует много кодировок. Но как их отличать?
Для этого в начало текста можно добавить специальный кодпоинт U+FEFF, он же Byte Order Mark (BOM), он же ZERO WIDTH NO-BREAK SPACE. По нему распознать кодировку очень просто.
В UTF-8 он имеет представление EF BB BF, в UTF-16LE — FF FE, в UTF-16BE — FE FF. Можно посмотреть на первые байты и понять, что за кодировка Юникода перед нами.
При этом, конечно же, чтобы не возникло никакой путаницы между little и big endian, кодпоинт U+FFFE валидным кодпоинтом не является и никогда не будет.
Использование BOM не обязательно, но в случае UTF-16 помогает различать endianness. В случае UTF-8 он помогает различать только сам факт наличия UTF-8, и используется редко.
Другие кодировки
Исторически существовали UTF-1 и UTF-7, но они уже давно не используются. Не будем останавливаться на них.
Также существует Punycode — способ использовать Юникод в доменных именах, которые разрешают только латинские буквы, цифры и дефис. Не будем его разбирать подробно. Отметим лишь, что café в Punycode будет caf-dma, а гепард — 80afec4ch. Дальше читайте сами.
Изредка используются и другие кодировки. Так, например, существует WTF-8, который похож на UTF-8, но считает непарные суррогаты валидными кодпоинтами. Используется, чтобы перекодировать имена файлов в Windows (которые могут потенциально содержать UTF-16 с непарными суррогатами) в UTF-8 (а в корректном UTF-8 суррогаты встречаться не должны вообще).
Чему равна длина строки?
Изучив графемные кластеры и кодировки, мы вплотную подошли к очень интересному и важному вопросу: как вычислить длину строки? Ответ на этот вопрос может отличаться в зависимости от того, что мы считаем:
- мы можем считать байты в UTF-8;
- мы можем считать пары байтов в UTF-16;
- мы можем считать кодпоинты;
- мы можем считать графемные кластеры.
Во всех четырех случаях ответ будет различаться.
А как в языках программирования? Все считают по-разному. Python считает в кодпоинтах, Go и Rust — в UTF-8 байтах, JavaScript — в UTF-16 парах байтов, Swift — в графемных кластерах. Подробнее можно почитать здесь. За деталями про свой любимый язык программирования обращайтесь к справочнику, гуглу, ChatGPT, астрологам или кому-нибудь еще, кто знает ответ.
Как перевернуть строку?
Вопрос неразрывно связан с предыдущим. Во многих языках есть функция reverse(), которая переворачивает строку, но что она переворачивает? Байты UTF-8, пары байтов UTF-16, кодпоинты, графемные кластера?
Очевидно, что байты или пары байтов переворачивать неправильно; после переворота строка почти наверное станет невалидным UTF-8/UTF-16, и будет состоять из «вопросиков» при попытке вывести ее на экран. Довольно бесполезный результат.
С кодпоинтами интереснее, но сейчас я докажу, что это тоже неправильный способ.
Пусть у нас такая строка: '🇬🇪🇦🇲'. Попробуем ее перевернуть:
>>> '🇬🇪🇦🇲'[::-1] # компактный способ перевернуть строку в Python
'🇲🇦🇪🇬'
Ой, а как мы так быстро с Кавказа в Сахару телепортировались?
Разгадка проста: каждый флаг — это графемный кластер из двух кодпоинтов. Дело в том, что флаги стран в Юникоде не закодированы напрямую. Вместо этого в Юникод добавили 26 специальных «букв» от A до Z. Если взять пару таких «букв» и записать ими код страны, то получится эмодзи флага этой страны.
Так вот, в нашем примере флаги Грузии и Армении записываются этими специальными «буквами» как 'GEAM'. Питон переворачивает строку как набор кодпоинтов и получает 'MAEG', то есть Марокко и Египет.
Значит, переворачивать строку на уровне кодпоинтов тоже неправильно. Выходит, единственный правильный способ — разбить строку на графемные кластера и записать их в обратном порядке.
Хотя, здесь необходимо задаться вопросом: а зачем вы вообще хотите перевернуть строку? Если вы реализуете какой-нибудь хитрый строковый алгоритм, чтобы уметь быстро искать подстроки в кодировке UTF-8, то скорее всего правильным решением может быть перевернуть ее именно как последовательность UTF-8 байтов. Так что все зависит от задачи.
Регистр
Ой, а что здесь рассказывать? Все очень просто и интуитивно! Есть верхний регистр и нижний, букву из верхнего регистра можно перевести в нижний и наоборот. А чтобы перевести строку в другой регистр, можно это сделать побуквенно. Давай к следующей теме!
А вот и нет. Все интереснее, чем вы думаете.
Во-первых, не всякая буква имеет верхний или нижний регистр. Например, китайские иероглифы, очевидно, не имеют регистра. Кириллица, латиница, греческий и армянский, очевидно, имеют регистр. В грузинском тоже есть верхний и нижний регистр с точки зрения Юникода, хотя используется не так, как мы привыкли в русском (в верхнем регистре обычно ПИШУТ ЗАГОЛОВКИ ЦЕЛИКОМ, а не выделяют начало предложения).
Во-вторых, в Юникоде существует не два регистра, а три! Третий называется титульным (title case). Например, у кодпоинта dž его верхний регистр — DŽ, а титульный — Dž.
В-третьих, перевод кодпоинта в нижний регистр не обязательно приводит к одному кодпоинту. Канонический пример из немецкого языка — U+00DF LATIN SMALL LETTER SHARP S, он же ß. Нетрудно убедиться, что
>>> 'ß'.upper()
'SS'
Правда, не так давно немцы придумали этому символу заглавный вариант ẞ, но обратную совместимость не отменишь, поэтому 'ẞ'.lower().upper() предсказуемо дает 'SS'.
Пример далеко не единственный: например, у кодпоинта ʼn при переводе в верхний регистр апостроф выделяется отдельно, и получается два кодпоинта ʼN. Аналогично, если преобразовать турецкое İ в нижний регистр, то получится два кодпоинта: обычное латинское i и U+0307 COMBINING DOT ABOVE, то есть точечка над буквой. Но случай турецкого İ настолько специальный, что мы его рассмотрим отдельно чуть-чуть позже.
В-четвертых, перевод строки в нижний регистр не всегда производится для каждого кодпоинта отдельно. В целом, это почти всегда так, но есть одно очень важное исключение: греческая Σ на конце слова пишется как ς, а в середине слова — как σ. Этот случай надо учитывать, и, например, в Rust его просто захардкодили. К счастью, это единственное исключение.
В-пятых, преобразование между регистрами может зависеть от языка! Самый важный пример — буквы I и İ в турецком и азербайджанском языках. Дело в том, что в этих языках строчная форма I — это ı (i без точки), а строчная форма İ — это i (уже с точкой). Буквы I и i используются самые обычные, из ASCII, но вот форма верхнего и нижнего регистра у них в турецком другая. Поэтому создатели Юникода добавили элегантное техническое решение костыль, и теперь, если у вас турецкая локаль, то функции tolower()/toupper() для вас будут работать чуть-чуть по-другому.
Стоит отметить, что эта точечка над турецким İ очень важна, и меняет чтение буквы (с точечкой она читается как «и», без нее — как «ы»). Известно, что пренебрежение этой точечкой как минимум один раз приводило к смерти людей!
Еще существует отдельное правило для литовского, где, например, Ì должно преобразовываться в i̇̀, а не в ì (т.е. появляется еще точечка), но это уже мелочь, от которой, я надеюсь, никто не умер.
К счастью, на момент написания поста в Юникоде больше таких специфичных для языка случаев нет.
Как его обрабатывают языки программирования? В Java результат toLowerCase() зависит от системной локали (т.е. можно получить неприятный сюрприз при попытке запустить свою программу на турецких компьютерах), в Python, кажется, не учитывает никак, в Rust тоже, в Go можно явно попросить использовать специфичные для турецкого правила.
В дополнение скажу, что разные языки могут иметь разные правила по поводу того, как писать слова с большой буквы, и никакой Юникод эти нюансы не покрывает. Да-да, даже если это европейский язык, использующий латиницу. Не верите? Тогда советую поплавать в озере IJselmeer (две заглавные буквы в начале!) и посетить славный город ‘s-Hertogenbosch. А еще полететь в ЮАР, которая на языке зулу называется iRiphabhuliki yaseNingizimu Afrika. Еще в некоторых языках надстрочные значки над буквами не пишутся, если буква становится заглавной, и это тоже не учтено в Юникоде. Википедия приводит еще несколько примеров из разных языков.
Как происходит преобразование?
Для реализации tolower()/toupper()/totitle(), конечно же, понадобится уже известная нам Unicode Character Database.
Во-первых, в файле UnicodeData.txt описаны простые случаи перевода в другой регистр, то есть такие, когда из одного кодпоинта после преобразования получается один кодпоинт, и общее их количество не изменяется.
Во-вторых, есть особый файл SpecialCasing.txt в котором описаны все непростые случаи (один кодпоинт преобразуется в два или более, греческая Σ, специальные правила для турецкого).
Конечно же, реализации tolower()/toupper() не используют эти файлы напрямую. Вместо этого обычно сначала генерируют таблицы преобразования, а потом вшивают их в исходный код библиотеки.
А еще часто строка состоит только из ASCII кодпоинтов, поэтому применяют оптимизацию: сначала быстро обрабатывают все ASCII-кодпоинты в начале строки (кстати, для случая ASCII существуют очень быстрые алгоритмы, например вот), а для остальных кодпоинтов уже используют более медленные таблицы.
Регистронезависимое сравнение строк
Частая задача — сравнить строки без учета регистра. Или искать строки в базе без учета регистра.
Как поступить? Может быть, перевести строку в верхний регистр? А может, в нижний? А может, в титульный?
Все эти три способа не всегда работают. Например, при переводе упомянутого выше ß в верхний регистр мы не заматчим строки, которые используют его современный заглавный эквивалент ẞ. А если переводить в нижний регистр, то мы не покроем случаи, когда вместо строчного ß записано заглавное SS.
И нет, этот случай с немецким языком далеко не единственный.
Что же делать?
На самом деле для этой задачи уже давно придумали решение. Оно называется case folding. Я не знаю, как этот термин из Юникода нормально переводится, поэтому дальше буду называть его просто кейсфолдинг.
Идея кейсфолдинга проста: вместо каждого кодпоинта исходной строки подставляется некоторая другая строка. Здесь нет никаких приколов с Σ (все три ее варианта становятся σ), с ß тоже все просто (она, как и ее заглавный вариант, преобразуется в ss). Далее, чтобы сравнить две строки без учета регистра, надо к обеим применить кейсфолдинг и просто посимвольно их сравнить. Выглядит просто, не так ли?
Регистронезависимый поиск строки делается аналогично: просто применяем кейсфолдинг ко всем строкам, а дальше, например, складываем преобразованные строки в хэш-таблицу и ищем там.
Строки после кейсфолдинга обычно не предназначены для того, чтобы показывать их пользователям на экране. Это внутреннее представление, его можно, например, хранить в базе или в какой-то структуре, чтобы выполнять поиск и сравнение.
Кейсфолдинг обратно совместим. Юникод гарантирует, что если строка состоит только из валидных кодпоинтов, которым в Юникоде уже присвоили значение, то в будущих версиях применение кейсфолдинга даст точно такой же результат. Для преобразования между регистрами это не так; в будущем у буквы может появится ее вариант в верхнем или нижнем регистре.
Как правило, кейсфолдинг преобразует все кодпоинты в нижний регистр. Но, бывают исключения. Например, символы азбуки чероки кейсфолдятся в верхний регистр. Почему так? Изначально символы чероки существовали в Юникоде только в виде верхнего регистра, а нижний добавили несколько версий позднее. Из-за обратной совместимости, чтобы кейсфолдинг существующих строк не изменился, используется верхний регистр.
Существует два вида кейсфолдинга: простой (simple, никогда не меняет длину строки) и полный (full, может изменить длину строки). Какой использовать — кажется, зависит от задачи и требований к скорости работы. Простой проще и быстрее в реализации, потому что он преобразовывает один кодпоинт в один, полный правильнее и покрывает больше случаев.
В целом в кейсфолдинге меньше крайних случаев, чем в преобразовании в другой регистр. Но случай с турецким (и азербайджанским) I остается, и если вы используете турецкий язык, то тогда надо применять особые правила кейсфолдинга.
К сожалению, кейсфолдинг реализован не во всех языках. Например, в Rust сравнения без учета регистра из коробки просто нет, есть только eq_ignore_ascii_case для случая с ASCII. Nim просто преобразовывает все в lowercase, не учитывая, к тому же, что один кодпоинт при этом может превратиться в несколько. В Go есть EqualFold, который использует простой кейсфолдинг и не умеет использовать полный. А вот Python здесь показывает себя лучше всех: у него есть метод casefold(), который умеет делать полный кейсфолдинг.
Как реализовать кейсфолдинг самому? Бинго! Опять с помощью Unicode Character Database! Релевантный для нас файлик — CaseFolding.txt, в нем описан сразу и простой, и полный кейсфолдинг. Не забываем про оптимизации в хорошем случае, если строка состоит только из ASCII.
Нормализация
Юникод — стандарт сложный и неоднозначный. Рассмотрим, например, букву Ä. Казалось бы, что может пойти не так? Ничего? А поверите ли вы, что
>>> 'Ä' == 'Ä'
False
Но почему False? Все просто: в первом случае мы имеем дело с одним кодпоинтом Ä, а во втором случае — с двумя: отдельно A, отдельно точечки над ней.
К счастью, авторы Юникода решили исправить возникший хаос и создали при этом еще больше хаоса придумали нормализацию. Да не одну, а аж четыре вида сразу! Сейчас мы их и рассмотрим.
Итак, четыре нормальные формы Юникода: NFC, NFD, NFKC и NFKD. В чем их различие?
Во-первых, они делятся на декомпозицию (NFD, NFKD) и композицию (NFC, NFKC). В первом случае выполняется полная декомпозиция всех кодпоинтов (например, Ä разделится на два кодпоинта), а во втором — после декомпозиции мы пытаемся еще собрать некоторые кодпоинты обратно (например, Ä в NFC останется одним кодпоинтом после того, как его разобрали и собрали обратно).
Во-вторых, есть варианты с K (kompatibility) и без K (canonical). В чем разница? На ранних этапах Юникода было важно сохранить совместимость с уже существующими кодировками, чтобы все символы из этих кодировок можно было один в один перевести в Юникод. По этой причине в Юникод добавили лигатуры (fi, fl), дроби (½, ¾) и прочие избыточные кодпоинты. Так вот, canonical варианты оставляют эти избыточные кодпоинты как есть, а compatibility варианты разделяют их на более простые кодпоинты (например, fi делится на f и i, а ½ становится тремя кодпоинтами 1⁄2).
После декомпозиции строки довольно легко сравнивать на эквивалентность. Например, приведем строки из примера выше в NFD:
>>> import unicodedata
>>> unicodedata.normalize('NFD', 'Ä') == unicodedata.normalize('NFD', 'Ä')
True
После нормализации строки оказались равны, как и ожидалось. Аналогично, после декомпозиции греческая омега и обозначение ома становятся эквивалентными:
>>> 'Ω' == 'Ω'
False
>>> unicodedata.normalize('NFD', 'Ω') == unicodedata.normalize('NFD', 'Ω')
True
Правда, не стоит ожидать от нормализации чуда. Например, если вы попытаетесь сравнить русское а и латинское a, то даже после нормализации получится False, потому что кодпоинты из разных письменностей принципиально друг в друга не нормализуются.
Интересный факт: macOS нормализует имена файлов в NFD. Остальные ОС такого не делают; а Linux вообще ничего не знает про кодировки в именах файлов и просто хранит сырые UTF-8 байты. Поэтому, если вам кто-то прислал файл с загадочным именем Важный отчет.pdf, вы легко можете определить, редактировали его на маке или нет. Дело в том, что в NFD буква й разбивается на два кодпоинта: и отдельно, ◌̆ отдельно.
Теперь, пожалуй, рассмотрим алгоритмы преобразования строки во все четыре нормальные формы.
NFD, NFKD
Процесс преобразования в NFD и NFKD аналогичен, разница лишь в том, что используются слегка разные данные.
Для каждого кодпоинта в UnicodeData.txt указана его декомпозиция. Декомпозиция бывает canonical, как, например, у U+0419 CYRILLIC CAPITAL LETTER SHORT I, она же Й:
0419;CYRILLIC CAPITAL LETTER SHORT I;Lu;0;L;0418 0306;;;;N;CYRILLIC CAPITAL LETTER SHORT II;;;0439;
Здесь 0418 и 0306 обозначает декомпозицию Й на И и ◌̆.
Также декомпозиция бывает compatibility, тогда перед непосредственно разбиением записано что-то <в угловых скобках>. Например, для ½, оно же U+00BD VULGAR FRACTION ONE HALF:
00BD;VULGAR FRACTION ONE HALF;No;0;ON;<fraction> 0031 2044 0032;;;1/2;N;FRACTION ONE HALF;;;;
Видим <fraction> в начале (т.е. это compatibility разложение по причине «дробь»), а также разложение на U+0031, U+2044 и U+0032. Список возможных значений в угловых скобках есть здесь в таблице 14, но нам он для дальнейшего рассказа неинтересен.
Так вот. В NFD используются только canonical разложения, а в NFKD — и canonical, и compatibility.
Насколько велико может быть разложение одного кодпоинта? Юникод гарантирует, что один кодпоинт раскладывается не более чем 18 кодпоинтов. Рекорд держит кодпоинт ﷺ, он же U+FDFA ARABIC LIGATURE SALLALLAHOU ALAYHE WASALLAM. Его compatibility разложение состоит из 18 арабских букв и пробелов: صلى الله عليه وسلم.
Но это еще не предел! Существует кодпоинт U+FDFD ARABIC LIGATURE BISMILLAH AR-RAHMAN AR-RAHEEM, он же ﷽. Да-да, это один кодпоинт! Его декомпозиция оказалась бы гораздо длиннее 18 кодпоинтов, но создатели Юникода применили мудрое решение костыль и сказали, что у этого кодпоинта не будет никакой декомпозиции.
Так, хватит с нас странных арабских символов. Разберем лучше сам алгоритм.
Сначала мы просто декомпозируем каждый кодпоинт согласно UnicodeData.txt, затем рекурсивно декомпозируем каждый кодпоинт результата, и так далее, пока не окажется так, что декомпозировать нечего. Здесь стоит отметить два важных момента. Во-первых, существуют кодпоинты, декомпозиция которых состоит из одного кодпоинта. Например, упомянутый выше кодпоинт ома Ω декомпозируется в заглавную греческую букву омега. Такие декомпозиции называются singleton. Во-вторых, декомпозиция слогов корейского хангыля в UnicodeData.txt не представлена, и ее необходимо вычислить отдельно с помощью несложного алгоритма.
Затем необходимо применить небольшую сортировку. Например, рассмотрим выдуманную мной только что букву Ą̄̂ (A с хвостиком снизу, и палочкой и крышечкой сверху). Она состоит из четырех кодпоинтов: буквы A, палочки, хвостика и крышечки. Но, казалось бы, хвостик и палочку можно поменять местами и получить такой же результат: 'Ą̄̂' (возможно, у вас на экране он не совсем такой же из-за багов отображения). А вот палочку и крышечку менять ни в коем случае нельзя, получится другая буква Ą̂̄. Мало ли как может поменяться значение слова от такого изменения!
Как сортировать? Для начала посмотрим для каждого кодпоинта на поле Combining Class в файлике UnicodeData.txt. Это поле в первом приближении показывает, куда значок прикрепляется к уже существующему символу. Например, для значков, расположенных над символом, Combining Class равен 230. Для букв, пробелов и других кодпоинтов, которые ни к чему не прикрепляются, он равен нулю. Полный список возможных значений можно глянуть здесь.
Теперь разобьем всю строку на группы, каждая из которых начинается с кодпоинта с Combining Class 0 (такие кодпоинты называются начальными или starters). Внутри каждой такой группы посортируем все кодпоинты по неубыванию Combining Class, при равенстве сохраняя относительный порядок. Например, в примере выше с Ą̄̂ порядок такой: буква A (класс 0), хвостик (класс 202), палочка (класс 230), крышечка (класс 230). Палочку и крышечку переставлять местами нельзя!
Вот и все, нормальная форма NFD Юникодной строки получена. Теперь рассмотрим NFC и NFKC.
NFC, NFKC
Чтобы получить NFC и NFKC, необходимо сначала получить декомпозицию (т.е. преобразовать строку в NFD для NFC и в NFKD для NFKC). Затем, после получения декомпозиции, надо применить процесс композиции, т.е. склеивания части кодпоинтов обратно в один.
Процесс композиции одинаков для NFC и NFKC.
Для начала выпишем все canonical декомпозиции. Это наши кандидаты на склеивание. Compatibility декомпозиции в склеивании не участвуют. Далее из кандидатов необходимо выкинуть так называемые исключения, которые в процессе композиции не участвуют. Например, необходимо удалить singleton’ы и случаи, когда два не-начальных кодпоинта склеиваются в один. Плюс еще некоторый небольшой список исключений. Полный их список приведен в файлике CompositionExclusions.txt.
В итоге остался некоторый список кандидатов на склеивание. После всех возможных исключений он состоит из троек (A, B, C), что означает, что кодпоинты A и B можно склеить в C, если они не блокируют друг друга. При этом кодпоинт A всегда начальный (т.е. с Combining Class 0). Кодпоинт B может быть тоже начальным, а может и не быть.
Что значит «блокируют друг друга»? Пусть cc(c) обозначает Combining Class кодпоинта c. Кодпоинт C заблокирован (blocked) от кодпоинта A, если cc(A) = 0 и между ними стоит кодпоинт B такой, что cc(B) = 0 или cc(B) ≥ cc(C). А поскольку мы работаем со строкой после ее декомпозиции, и все кодпоинты посортированы по Combining Class, то достаточно лишь проверить, что кодпоинт непосредственно перед C не имеет такой же Combining Class, и что между A и C нет других начальных кодпоинтов.
Как это правило понимать интуитивно? Вернемся к нашему примеру с буквой Ą̄̂, у которой сверху палочка и крышечка. Во-первых, мы не хотим, чтобы крышечка досталась другой букве, поэтому между нашей буквой и крышечкой не должно быть других начальных кодпоинтов. Во-вторых, мы не хотим, чтобы палочка и крышечка поменялись местами, поэтому мы не даем объединить A с крышечкой (а это как раз второе условие с cc(B) ≥ cc(C)).
Дальше все просто: мы ходим по декомпозированной строке по порядку и пробуем каждый кодпоинт объединить с предыдущим начальным кодпоинтом, если это возможно и если объединение не заблокировано. Заметим при этом, что для объединения двух кодпоинтов в один они не обязательно должны идти подряд.
При правильной реализации алгоритм выше работает строго за линейное время.
Свойства нормальных форм
Во-первых, все нормальные формы идемпотентны: применение той же самой нормальной формы второй раз не изменит строку.
Во-вторых, применять нормализацию можно несколько раз, и это не изменит строку. Так, NFD(NFC(x)) = NFD(x) и NFC(NFD(x)) = NFC(x). Аналогично с NFKC и NFKD.
В-третьих, после применения NFC и NFD, можно применить NFKC и NFKD, и это будет эквивалентно их применению к исходной строке. Так, NFKD(NFD(x)) = NFKD(NFC(x)) = NFKD(x) и NFKC(NFD(x)) = NFKC(NFC(x)) = NFKC(x).
В-четвертых, нормализация обратно совместима: при обновлении версии Юникода нормальная форма уже существующих строк останется прежней. Combining Class всех существующих кодпоинтов тоже никак не изменяется.
Но при этом стоит отметить, что NFD(X) + NFD(Y) = NFD(X+Y) выполняется далеко не всегда, то же самое с другими нормальными формами. Например, строка Y может начинаться с не-начального кодпоинта, который переупорядочится при сортировке во время нормализации.
Еще про поиск
Поговорим еще про поиск и сравнение строк.
Вы часто слушаете музыку? Я очень. Иногда мне хочется включить какую-то песню, зная ее название. Тогда я, понятное дело, использую поиск. Обычно названия песен устроены довольно просто — обычные слова из русских или английских букв (реже — цифр). Ну разве что иногда требуется заменить русское е на ё и наоборот. Но иногда мне хочется послушать группу Magma, например Da Zeuhl Ẁortz Mëkanïk из альбома Mëkanïk Dëstruktïẁ Kömmandöh.
Magma — группа довольно необычная. Они исполняют песни на выдуманном языке (кобайском). Группа была основана… Ладно, я отвлекся от темы, все-таки этот пост про тонкости Юникода, а не про творчество Magma. Короче, они в названиях песен используют очень много надстрочных значков над буквами, набирать которые на клавиатуре проблематично. Когда я ищу их песни, я хочу просто вбить в поиск «da zeuhl wortz mekanik», и не вспоминать, над какими буквами надо еще точечки поставить, чтобы все нашлось.
Проблема касается не только малоизвестной и странной Magma, например, любители метäлä знают, чтö некöтöрые грÿппы öчень любят умлäуты.
Итак, нам необходимо как-то удалить все надстрочные значки. Что мы будем делать? Ïss ïss ëhnwöhl ëss ëss’ Ühnwëhl, ой, то есть переведем строку в NFKD, а потом удалим все кодпоинты категории M (надстрочные значки как раз этой категории и принадлежат). И не забудем применить кейсфолдинг, чтобы поиск был регистронезависимым.
Примерно так делает, например, расширение FTS3 для полнотекстового поиска в SQLite. Правда, авторы SQLite используют TCL, чтобы парсить Unicode Character Database, но это уже так, мелочи жизни.
Подозреваю, остальные решения для полнотекстового поиска умеют удалять надстрочные значки примерно таким же образом.
Конечно же, для полноценного поиска такой нормализации недостаточно: в идеале надо уметь исправлять опечатки пользователя, а еще уметь обрабатывать случаи, когда ответ подходит по смыслу, но не дословно. В случае поиска по музыке может вообще хотеться, чтобы ты ему напел та-та-та-та-та-та, а он тебе выдал нужную песню. Впрочем, это пост про Юникод, а не про поиск, поэтому не будем отвлекаться.
Слева направо и справа налево
Мы привыкли писать текст слева направо. Но некоторые языки практикуют написание справа налево. Юникоду, чтобы быть поистине универсальным, необходимо поддерживать оба варианта написания.
На самом деле существуют еще языки, которые пишутся сверху вниз (например, монгольский). К счастью, создатели Юникода решили это не реализовывать, иначе разработчики движков отрисовки текста сошли бы с ума. Да и остальные люди, которым пришлось бы все это учитывать, тоже.
Поэтому с точки зрения Юникода по большому счету существует всего два направления текста: слева направо и справа налево.
Я не хочу рассматривать эту тему слишком подробно, но кое-что упомянуть необходимо. Если очень интересно, можно заглянуть в подробное описание, как правильно рендерить текст, когда в одном документе смешивают порядок слева направо и справа налево.
Во-первых, у каждого кодпоинта есть свойство Bidi Class, которое задает, как его обрабатывать. Возможные значения можно посмотреть здесь. Видно, что случаев достаточно много: некоторые кодпоинты пишутся всегда слева направо, некоторые — справа налево, некоторые безразличны к порядку, плюс много отдельных классов для учета каких-то тонкостей. Так, разные виды цифр и арабские буквы почему-то вынесены в отдельный класс.
Существуют и специальные контрольные кодпоинты, которые позволяют изменить порядок следования текста:
- U+202A LEFT-TO-RIGHT EMBEDDING
- U+202B RIGHT-TO-LEFT EMBEDDING
- U+202C POP DIRECTIONAL FORMATTING
- U+202D LEFT-TO-RIGHT OVERRIDE
- U+202E RIGHT-TO-LEFT OVERRIDE
- U+2066 LEFT‑TO‑RIGHT ISOLATE
- U+2067 RIGHT‑TO‑LEFT ISOLATE
- U+2068 FIRST STRONG ISOLATE
- U+2069 POP DIRECTIONAL ISOLATE
Еще стоит отметить, что некоторые символы умеют «переворачиваться», если текст вокруг использует порядок справа налево. Например, скобочка ( в арабском тексте будет отображаться как ).
Этого, пожалуй, хватит для базового понимания. Закончу тему вот этим комиксом с xkcd:

Теперь пойдем дальше…
Ой, то есть теперь пойдем дальше.
Юникод в исходном коде программ
Мое мнение: в любом языке программирования в именах переменных, функций, классов и так далее, должны быть только символы ASCII. Никакой кириллицы и никаких эмодзи!
Но, увы, прогресс остановить нельзя, а на дворе XXI век. Многие популярные языки программирования обзавелись возможностью использовать Юникод в своих идентификаторах.
Что для этого предлагает стандарт Юникода? Во-первых, он определяет два множества кодпоинтов: XID_Start и XID_Continue. Предполагается, что идентификаторы будут начинаться с кодпоинта из множества XID_Start, а дальше будут идти кодпоинты из множества XID_Continue.
Так, Rust определяет идентификаторы и ключевые слова как
IDENTIFIER_OR_KEYWORD: XID_Start XID_Continue* | _ XID_Continue+
При этом, если внимательно почитать документ выше, можно заметить, что в некоторых особых случаях Rust разрешает только ASCII.
Python аналогично использует XID_Start и XID_Continue.
Go разрешает только кодпоинты категорий L и Nd (т.е. буквы и десятичные цифры). А еще в Go есть дополнительный прикол: все публичные функции должны начинаться с заглавной буквы (т.е. c категорией Lu). Получается, что китайский язык нельзя полноценно использовать в идентификаторах. На эту тему даже есть issue!
Также необходимо нормализовать идентификаторы. В соответствующем документе от авторов Юникода рекомендуется NFC или NFD, но не NFKC и не NFKD. Rust, например, использует NFC. Python использует NFKC. А Go не использует нормализацию, потому что не разрешает в идентификаторах надстрочных значков отдельными кодпоинтами. Только буквы и цифры. Поэтому можно как бы считать, что Go требует NFC (с дополнительными ограничениями) от программиста, но сам ничего не нормализует.
Тем не менее, даже с нормализацией Юникода можно весело пранковать коллег. Например, заменить местами латинскую букву a на русскую и наблюдать за реакцией. Главное — самому не попасться в свою же ловушку, а то можно долго залипать в, казалось бы, работающий код, и недоумевать, почему компилятор швыряется ошибками :) Подобных пранков можно придумать еще много, например, можно заменить точку с запятой на символ ;, он же U+037E GREEK QUESTION MARK.
Еще более веселый пранк — вставить кодпоинты U+2066 LEFT-TO-RIGHT ISOLATE и смотреть, как комментарии чудесным образом оказываются совсем не комментариями.
Или вставить куда-нибудь в середину идентификатора невидимый кодпоинт U+200B ZERO WIDTH SPACE.
К счастью, разработчики некоторых компиляторов и линтеров не любят такие формы развлечения и пытаются их пресечь. Скажем, Rust заботится о вашей безопасности не только при помощи borrow checker’а, и при попытке вставить русское а в английский идентификатор честно кинет предупреждение. Rust также запрещает подобные на U+2066 кодпоинты в исходниках. Многие другие языки, например, Go и Python, с этим ничего не делают, но проблему технически можно решить нормальным линтером. Или даже простым bash-скриптом (при отсутствии линтера).
Существует также спецификация, как обнаруживать подобного рода пранки, когда строки выглядят одинаково, а на деле не совпадают даже после нормализации.
Символы-призраки
В Юникоде существуют так называемые символы-призраки — не имеющие никакого смысла символы, которые каким-то образом проникли в стандарт.
Например, это касается некоторых японских иероглифов. Многие из них — это ошибочные написания реально существующих иероглифов, и именно в таком ошибочном виде их и включили в Юникод. Даже несмотря на то, что эти иероглифы лишены смысла, а исправленные версии добавили позже отдельными кодпоинтами, в стандарте они останутся уже навсегда.
Еще один такой кодпоинт — U+237C RIGHT ANGLE WITH DOWNWARDS ZIGZAG ARROW, он же ⍼. Его еще иногда называют Angzarr, потому что ему такое имя дали в XML. Никто не знает, что означает этот загадочный кодпоинт. Можете почитать расследование, откуда он вообще взялся в Юникоде (в четырех частях): раз, два, три, четыре. Не обижайте Angzarr’а, он хороший.
Несколько вариантов отображения одного и того же символа
Постойте, а такое вообще бывает? Казалось бы, символ есть символ, и Юникод как раз был разработан, чтобы одни и те же символы у всех людей в мире выглядели одинаково!
Естественно, бывает! Люди могут использовать разные шрифты, и даже внутри одного шрифта начертание может различаться, потому что часть текста оказалась выделена жирным или курсивом. Отдельный мем — в разных шрифтах по-разному нарисованы эмодзи, и иногда может возникнуть недопонимание, потому что собеседник видит у себя ваши эмодзи немного по-другому.
Окей, пускай шрифт один и тот же, а жирный и курсив мы не используем. Что еще мы не учли?
Вариантные селекторы
В Юникоде существует 16 специальных кодпоинтов, называемых вариантные селекторы (variation selector). Их имена выглядят просто: от VARIATION SELECTOR-1 до VARIATION SELECTOR-16.
Чтобы применить вариантный селектор на кодпоинт, необходимо дописать его после нужного кодпоинта.
Не все из вариантных селекторов используются. На данный момент имеют хоть какой-то смысл только селекторы номер 1, 2, 3, 4, 7, 15 и 16. Ну и конечно же, их действие не распространяется на все кодпоинты, только на некоторые. А еще они могут иметь разный смысл в зависимости от кодпоинта, на который применяются.
Особое значение имеют селекторы номер 15 и 16. Селектор 15 всегда говорит, что кодпоинт надо отображать по возможности черно-белым, а селектор 16 — что кодпоинт надо по возможности отображать как эмодзи.
Например, возьмем U+263A WHITE SMILING FACE. С селектором 15 он имеет вид ️☺︎, а с селектором 16 — ☺️. А кодпоинт U+265F BLACK CHESS PAWN имеет варианты ♟︎ и ♟️.
Больше примеров можно увидеть здесь. А мы пока пойдем дальше.
Все валидные способы использовать вариантные селекторы, конечно же, описаны в Unicode Character Database. Релевантные файлы — StandardizedVariants.txt и emoji/emoji-variation-sequences.txt (отдельный файл для эмодзи).
Зависимость от языка
На этом странности не заканчиваются! Оказывается, отображение символов Юникода может зависеть и от языка!
Это наглядно показывает твит от @nikitonsky:
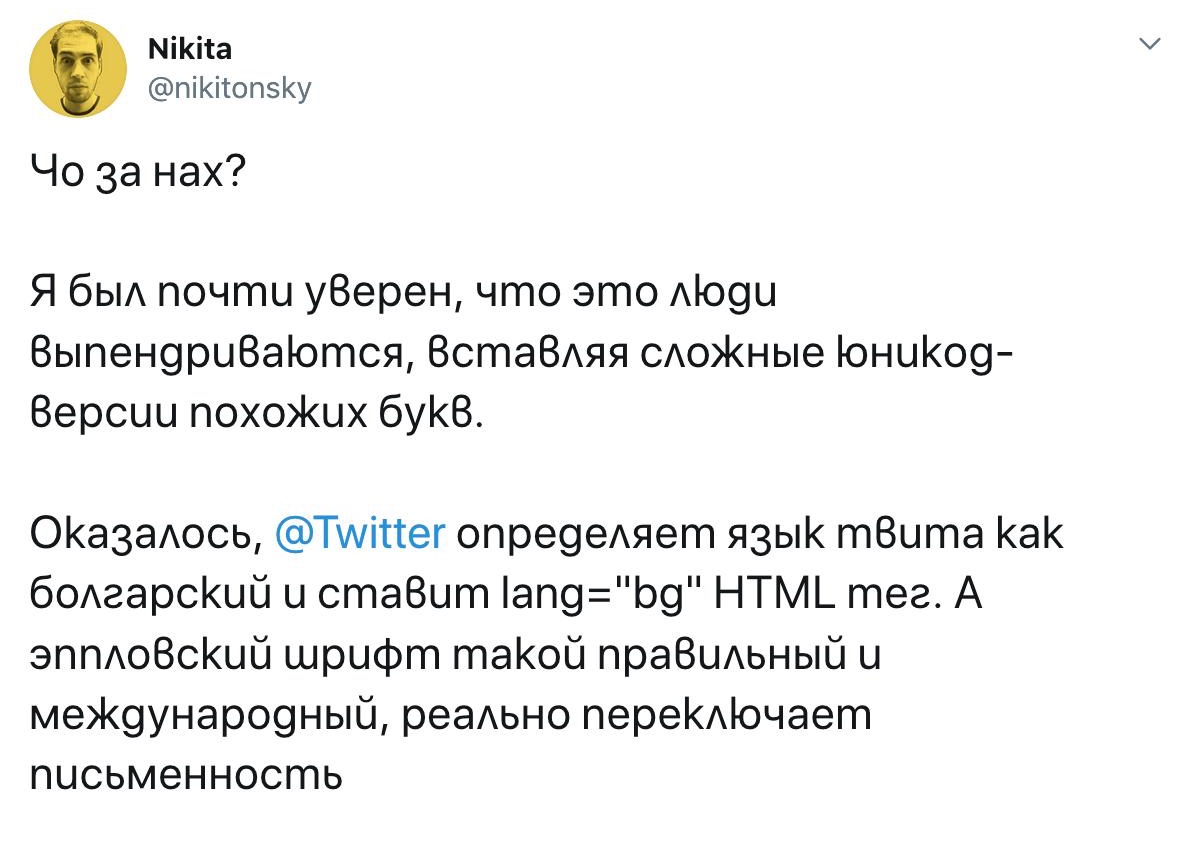
Эффект проявляется далеко не всегда; такие языковые вариации поддерживаются далеко не всеми шрифтами. Например, в моем браузере твит выше отображается точно так же вне зависимости от того, там стоит русский язык или болгарский.
Оказывается, кириллица не везде одинакова: сербы и болгары пишут некоторые буквы несколько по-другому. Это, например, хорошо заметно на примере буквы «б», которая упоминалась в начале поста. А на Википедии есть сравнение написания одних и тех же букв в разных славянских языках.
Впрочем, все эти различия в кириллице довольно незначительны и сильного затруднения при чтении текста не вызывают. А вот с иероглифами дело обстоит несколько веселее. Как известно, примерно похожий набор иероглифов используется во многих азиатских языках: китайском, японском, корейском, вьетнамском (хотя последние два чаще всего используют свой алфавит, а не иероглифы). Иногда в разных странах одни и те же иероглифы пишутся немного по-другому. Создатели Юникода, увидев это, решили взять и объединить все региональные варианты написания одного и того же иероглифа в один кодпоинт. Унификация — это, конечно, хорошо, но теперь иногда текстам надо явно указывать язык, чтобы иероглифы в нем показывались правильно.
Как указать, на каком языке написан текст, чтобы он правильно отобразился? Юникод не дает ответа не этот вопрос, и придется читать документацию программы/библиотеки, с помощью которой вы отрисовываете текст. Например, для HTML можно написать что-то вроде <div lang="ru">, чтобы указать, что текст внутри секции написан на русском. Или можно не париться и надеяться, что современные технологии сами отгадают язык из контекста или системных настроек (это часто работает неидеально).
Кстати, правильно указывать язык в HTML может быть полезно по другим, не связанным с Юникодом причинам (раз, два), но я немного отклоняюсь от темы.
«Шрифты» в Юникоде
Внутри Юникода существуют свои «шрифты»! Например:
- полужирный: 𝐔𝐧𝐢𝐜𝐨𝐝𝐞
- курсивный: 𝑈𝑛𝑖𝑐𝑜𝑑𝑒
- полужирный курсивный: 𝑼𝒏𝒊𝒄𝒐𝒅𝒆
- рукописный: 𝒰𝓃𝒾𝒸ℴ𝒹ℯ
- еще рукописный: 𝓤𝓷𝓲𝓬𝓸𝓭𝓮
- готический: 𝔘𝔫𝔦𝔠𝔬𝔡𝔢
- полужирный готический: 𝖀𝖓𝖎𝖈𝖔𝖉𝖊
- контурный: 𝕌𝕟𝕚𝕔𝕠𝕕𝕖
- без засечек: 𝖴𝗇𝗂𝖼𝗈𝖽𝖾
- полужирный без засечек: 𝗨𝗻𝗶𝗰𝗼𝗱𝗲
- курсивный без засечек: 𝘜𝘯𝘪𝘤𝘰𝘥𝘦
- полужирный курсивный без засечек: 𝙐𝙣𝙞𝙘𝙤𝙙𝙚
- моноширинный: 𝚄𝚗𝚒𝚌𝚘𝚍𝚎
- широкий: Unicode
- в квадратиках: 🅄🄽🄸🄲🄾🄳🄴
- еще в квадратиках: 🆄🅽🅸🅲🅾🅳🅴
- в кружочках: Ⓤⓝⓘⓒⓞⓓⓔ
- еще в кружочках: 🅤🅝🅘🅒🅞🅓🅔
И нет, в списке выше я не менял шрифт посреди текста. Я всего лишь использовал разные кодпоинты Юникода. Честно-честно.
Cтоит учитывать, что все эти «шрифты» в большинстве своем поддерживают лишь латинские буквы. Иногда еще греческие буквы. Изредка — цифры.
Зачем это вообще добавили в Юникод? Кодпоинты из всех примеров, кроме последних пяти, имеют в своем названии слово MATHEMATICAL, а значит, предназначены для использования во всяких математических формулах. А там начертание символа может серьезно менять смысл. Например, буквами K, 𝕂, 𝓚, 𝙺 и 𝕶 могут обозначаться совсем разные математические объекты, и важно их не перепутать!
Как отсортировать строки лексикографически
Во-первых, надо знать язык. В разных языках лексикографический порядок может сильно различаться, даже если используются одни и те же символы.
Во-вторых, Юникод вам здесь никак не поможет. Но если очень хочется, то читайте дальше.
За пределами Юникода
Есть вещи, которые Юникод не покрывает. Например, лексикографический порядок слов. Или правила написания слов с большой буквы. Или как транслитерировать названия с одного языка на другой.
Эту задачу решает другой проект, который называется CLDR. Он включает в себя огромное количество данных для всех языков мира. Он позволяет решать описанные выше задачи, а также записывать числа словами, использовать правильный для языка формат даты и времени и многое другое. Штука полезная, но очень массивная.
Как воспользоваться CLDR? Например, можно подключить упомянутую в начале библиотеку ICU, в которой все это реализовано. Библиотека работает нативно для Си, C++ и Java, а для остальных языков необходимо поискать или написать самому биндинги к сишной libicu.
Еще можно почитать соответствующие стандарты и реализовать все с нуля, но это долго и трудно.
Вместо эпилога
СЛОЖНО, СЛОЖНО, ВСЕ ОЧЕНЬ СЛОЖНО, КРАЙНЕ ЗАПУТАНО И ЧРЕЗВЫЧАЙНО НЕИНТУИТИВНО
ВАВИЛОНСКАЯ БАШНЯ БЫЛА ОШИБКОЙ
КОМПЬЮТЕРЫ ТОЖЕ
ААААААА, ПОЧЕМУ ЭТО ВСЕ ВООБЩЕ СУЩЕСТВУЕТ
ЧЕЛОВЕЧЕСТВО СОЗДАЛО МОНСТРА, КОТОРОГО НЕ ПОНИМАЕТ 99.99% ЛЮДЕЙ, НО ТЕМ НЕ МЕНЕЕ, ПОВСЕМЕСТНО ИСПОЛЬЗУЕТ
КТО-НИБУДЬ, ПЕРЕВЕДИТЕ ВСЕ ЯЗЫКИ МИРА НА ОБЫЧНУЮ ЛАТИНИЦУ БЕЗ ДОПОЛНИТЕЛЬНЫХ ЗНАЧКОВ И ЗАКОПАЙТЕ ВСЮ ЭТУ СЛОЖНОСТЬ
ĄÄÃÂÅĂÁÀ!!!¡!ꜝ‼İ
🐳🐳🐳🐳🐳🐳🐳🐳🐳🐳🐳🐳
Благодарности
Спасибо Ване @vanyakhodor и Илье @optozorax за вычитывание поста и ценные замечания.
Спасибо всем внимательным читателям, кто указал мне на неточности в посте.
Также спасибо всем подписчикам @gepardchan за то, что подписаны и читаете меня :)